







java集合
本文主要介绍了java集合框架,具体介绍了Collection接口,Map接口及其子接口
基本概念
- Java 集合框架包括两种类型的容器,Java集合就像一种容器,可以存储多个对象到集合中
- java5之后对集合增加了泛型,可以设置对象数据类型
- Collection和Map是Java集合框架的根接口
- 集合(Collection),存储元素集合
- 图(Map),存储键/值对映射
Collection接口
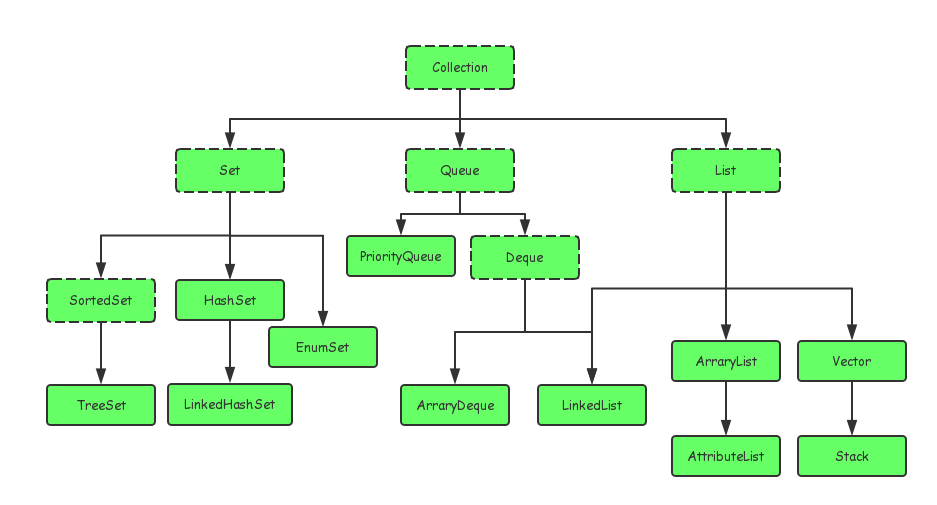 迭代器Iterator,用于遍历集合,collection实现了Iterator
迭代器Iterator,用于遍历集合,collection实现了Iterator
list 有序可重复
ArrayList
- ArrayList是一个动态扩展的数组,Vector也同样如此
Vector & ArrayList
相同点:
-
ArrayList和Vector都是继承了相同的父类和实现了相同的接口
-
底层都是数组实现的
-
初始默认长度都为10。
不同点:
-
Vector是同步的(Synchronized),线程安全的而ArrayList的方法不是,ArrayList的性能比Vector好。
-
Vector或ArrayList元素超过初始大小时,Vector容量翻倍,而ArrayList增加50%,ArrayList节约内存空间。
-
Vector可以设置增长因子capacityIncrement,ArrayList不可以
ArrayList & LinkedList(LinkedList还实现了Deque接口,可当作双端队列来使用,也可以当队列使用。)
-
ArrayList动态数组数据结构,而LinkedList链表数据结构
-
随机访问get和set,ArrayList要优于LinkedList,因为LinkedList要移动指针
-
LinkedList更加适用于插入、删除大量元素
-
两者线程不安全,如果需要线程安全版本,ArrayList对应的是CopyOnWriteArrayList,LinkedList对应的是ConcurrentLinkedQueue;
-
ArrayList开销在于结尾浪费一定空间,而LinkedList开销在于需要存储结点信息以及结点指针信息;
Iterator遍历
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()) {//判断是否有下一个元素
String str = iterator.next();
System.out.println(str);
}
Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量
for循环遍历时
Stack
- Stack继承Vector,用于模拟“栈”,“后进先出”(LIFO)。
Set
HashSet是Set接口的典型实现,HashSet按Hash算法来存储集合中的元素。因此具有很好的存取和查找性能。
HashSet
-
无序
-
HashSet不同步的
-
集合元素值可以是null。
-
HashSet判断两个元素是否相等的标准是两对象通过equals()相等,并且两对象hashCode()方法返回值相等。
equals()和hashCode()
equals()
equals()比较两个对象是否相等 Object中的equals是比较两个对象的地址是否相等,实现如下
public boolean equals(Object obj) {
return (this == obj);
}
所以,如果对象没有重写equals方法,就等价于“==”方法,比较对象的地址是否相等
如String、 Integer、Double、Math重写了Object中的equals方法,所以比较的是内容
hashCode()
- hashCode() 作用获取哈希码,也称散列码,实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置
- hashCode() 定义在JDK的Object.java中,所以所有类都有hashCode()
- 若没有覆盖hashCode()方法,比较两个对象是不是同一个对象,等价“==”,即对象内存地址是否相同。
HashSet中判断集合元素相等
- 两个元素equal()false,hashCode()方法返回不相等,HashSet将会把它们存储在不同的位置
- 两个元素equal()true,hashCode()方法返回不相等,HashSet将会把它们存储在不同的位置
- 两个元素equal()false,hashCode()方法返回相等,HashSet将会把它们存储在相同的位置,以链表式结构来保存多个对象
- 两个元素equal()true,hashCode()方法返回相等,HashSet将不允许添加
LinkedHashSet
- LinkedHashSet是HashSet对的子类,使用链表维护元素的次序,有序,性能低于HashSet
TreeSet
- TreeSet是SortedSet接口的实现类,有序
Comparable接口
compareTo(Object obj)决定顺序,
obj1.compareTo(obj2) == 0 则相等
obj1.compareTo(obj2) > 0 则obj1 > obj2
obj1.compareTo(obj2) < 0 则obj1 < obj2
自然排序
- 升序排列,即通过compareTo(Object obj)方法比较后大的的往后排
自定义排序
创建TreeSet时,调用一个带参构造器,传入Comparator对象
Comparator<Person> comparator = new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
if(o1.age<o2.age){
return 1;
}else if(o1.age>o2.age){
return -1;
}else{
return 0;
}
}
};
TreeSet<Person> set = new TreeSet<Person>(comparator);
也可Person实现Comparable接口,重写compareTo(Object obj)
EnumSet
- 专为枚举类设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,有序。
性能
EnumSet性能>HashSet性能>LinkedHashSet>TreeSet性能
Queue
- Queue用于模拟队列这种数据结构,队列通常是指“先进先出”(FIFO),队列不允许随机访问队列中的元素。
PriorityQueue
- PriorityQueue保存队列元素顺序不是加入队列顺序,而是按队列元素的大小重新排序。因此当调用peek()或pool()方法取出最小的元素,队列的头最小
- 当PriorityQueue中没有指定Comparator时,加入元素必须实现了Comparable接口(即元素是可比较的),否则会导致 ClassCastException。
Comparator<Integer> cmp = new Comparator<Integer>() {
public int compare(Integer e1, Integer e2) {
return e2 - e1;
}
};
PriorityQueue<Integer> q2 = new PriorityQueue<Integer>(5,cmp);
Deque与Queue、Stack的关系
- 当 Deque 当做 Queue队列使用时(FIFO),添加到队尾,删除头部元素
- Deque 也能当Stack栈用(LIFO),建议用Deque代替Stack
Map(key-value)
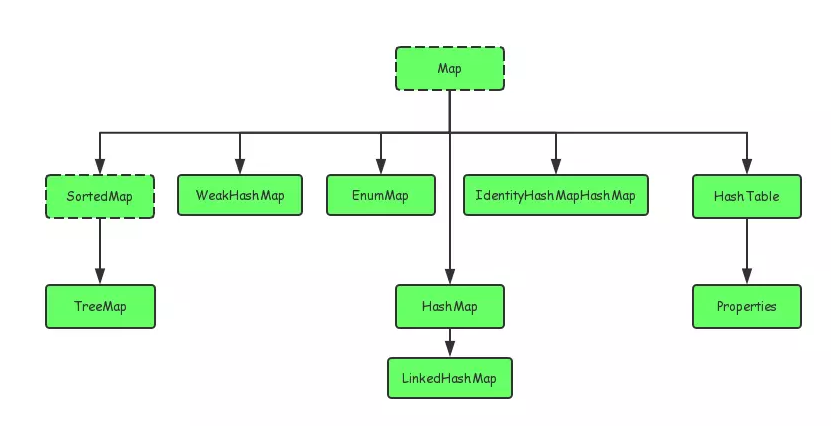
map介绍
-
keys是个set集合,所以不重复
-
keySet()获取所有key组成的set集合
-
map.values()是Collection
-
Map中内部类Entry(key-value)
HashMap
- HashMap 是一个散列表(key-value)
- key判断相等的标准参照HashSet
HashMap & Hashtable
- Hashtable是一个线程安全,HashMap是线程不安全,HashMap性能好
- Hashtable不允许使用null作为key和value,NullPointerException,HashMap可以使用null作为key或value。
HashMap遍历
for (Integer in : map.keySet()) {
String str = map.get(in);
}
Iterator<Map.Entry<Integer, String>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<Integer, String> entry = it.next();
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
for (Map.Entry<Integer, String> entry : map.entrySet()) {
System.out.println("key= " + entry.getKey() + " and value= " + entry.getValue());
}
for (String v : map.values()) {
System.out.println("value= " + v);
}
LinkedHashMap
- LinkedHashMap是HashMap子类,LinkedHashMap使用双向链表来维护key-value对的次序。
- LinkedHashMap=散列表+循环双向链表
TreeMap
- TreeMap是SortedMap接口的实现类,通过红黑树实现的,每个key-value对即作为红黑树的一个节点。
- TreeMap中判断两个key相等的标准是:两个key通过compareTo()方法返回0
TreeMap排序方式和TreeSet一样
IdentityHashMap
- 比如k1和k2,当且仅当k1==k2的时候,IdentityHashMap才会相等,而对于HashMap来说,相等的条件是:(k1==null ? k2==null : k1.equals(k2))。
- IdentityHashMap.put(new String("str"))
- 无序,线程不安全,Collections.synchronizedMap(new IdentityHashMap(...))实现线程安全
个人经验
//IdentityHashMap可以存在相同的key 获取key相同的对象放到list
public <T> List<T> getMapToList(IdentityHashMap<String, T> identityHashMap, String code) {
List<T> list = new ArrayList<T>();
for (Map.Entry<String, T> entry : identityHashMap.entrySet()) {
if (entry.getKey().equals(code)) {
list.add(entry.getValue());
}
}
return list;
}

