


-
一,parmary&replica的自动负载均衡
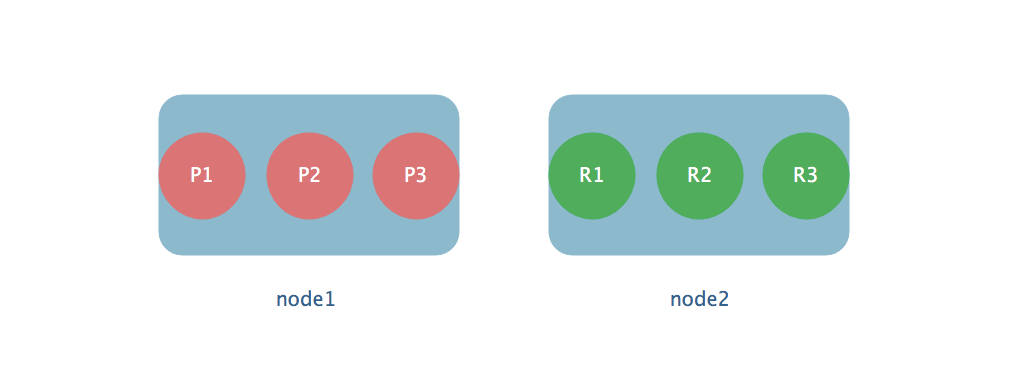
比如我们现在这里有两个节点,一共有3个primary shard和3个replica shard,priamry 和 replica 分开存放
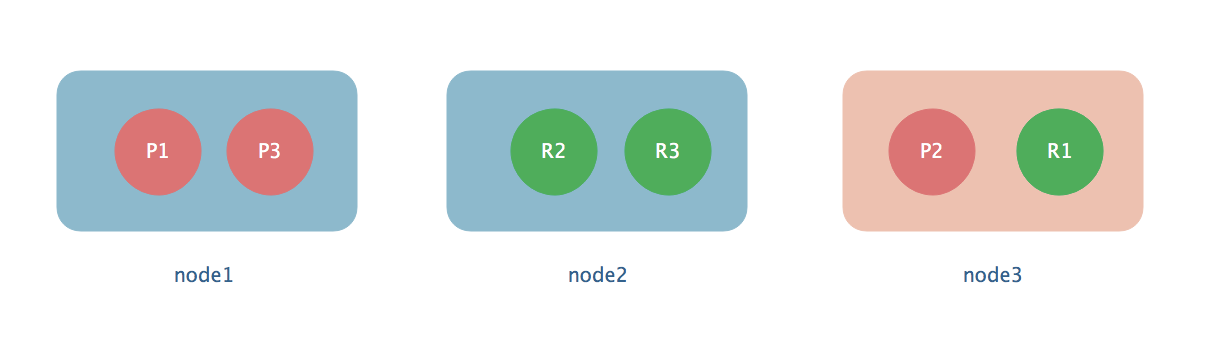
 现在集群加入一个新节点,node3,那么ES会自动将我们的所有分片给负载均衡,尽量的让每个节点上面的分片数量达到一致, 那么重新分配过后很有可能就是下面这样了。扩容之后每个节点占用的IO/CPU/MEMERY将会更少,所以性能就更好。
现在集群加入一个新节点,node3,那么ES会自动将我们的所有分片给负载均衡,尽量的让每个节点上面的分片数量达到一致, 那么重新分配过后很有可能就是下面这样了。扩容之后每个节点占用的IO/CPU/MEMERY将会更少,所以性能就更好。
-
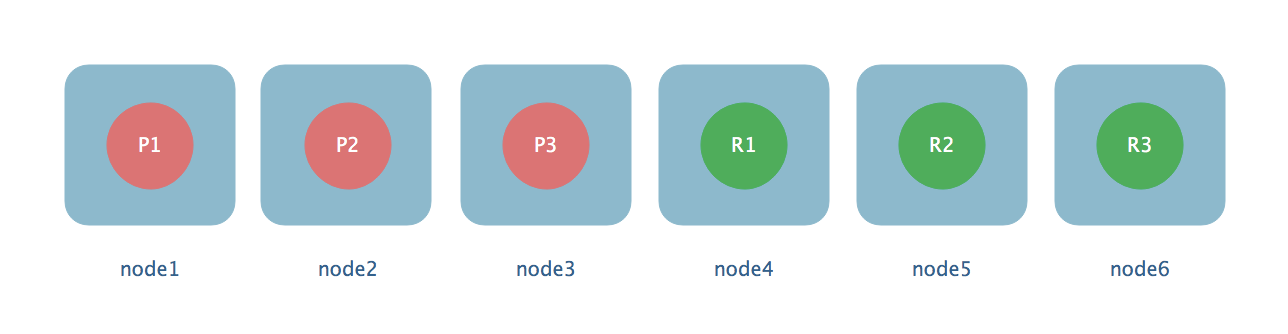
二,扩容的极限,6个shard(3 primary, 3 replica),最多扩容到6台机器,每个shard可以占用服务器的所有资源,性能最好(还可以超出扩容极限,动态修改replica shard数量为6个(3个primary shard 和 6个replica shard),扩容到9台机器后,比3台机器拥有3倍的吞吐量)。
如果我们现在有6个shard,3个primary 和 3个replica 那么最大的扩容极限是6台机器,让他们每台机器的性能最大化。
-
三,三台机器下,9个shard,(3个primary,6个replica shard)资源更少,但是容错性更好,最大可以允许两台机器宕机,6个shard只能容忍一台机器宕机
提升系统的容错性,现在是3台机器,9个shard(3个primary和6个replica shard)。
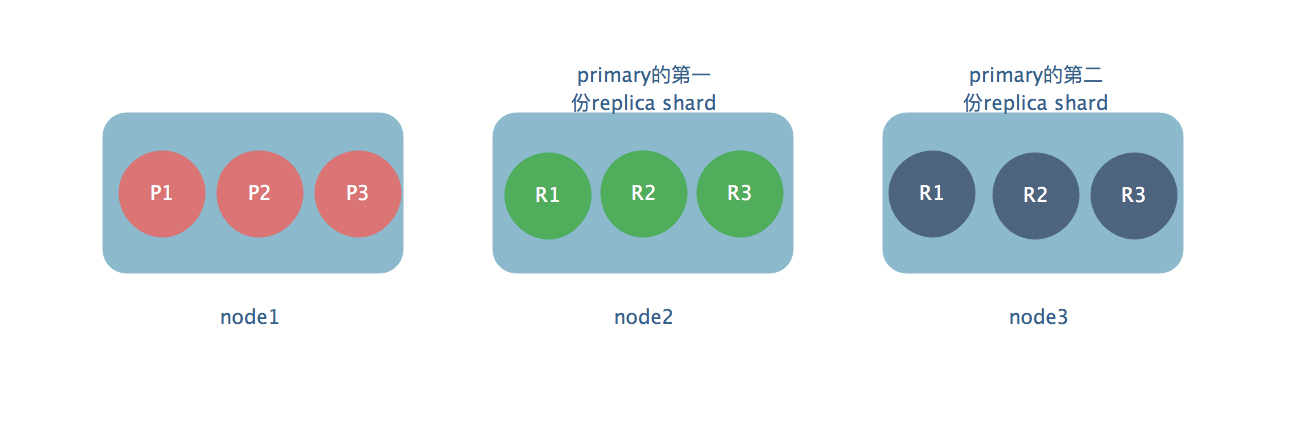 这个时候如果node1宕机了,那么还会有两个节点可以获取数据,还可以在node2和node3两个节点里面在允许一次宕机
这个时候如果node1宕机了,那么还会有两个节点可以获取数据,还可以在node2和node3两个节点里面在允许一次宕机
阴鸦
文章:102
关注:0 粉丝:5




八,ElasticSearch横向扩容过程,如何超出扩容极限,以及如何提升容错性能
发布时间: 更新时间:


目录
标题