介绍
本文将分三步来讲解在elasticsearch集群中,如果当master节点宕机过后,replica如何选举出一个新的master,然后在将已经丢失的数据进行恢复。
现在是3台机器,6个shard(3个primary 和 3个 replica),其中的master节点宕机了。
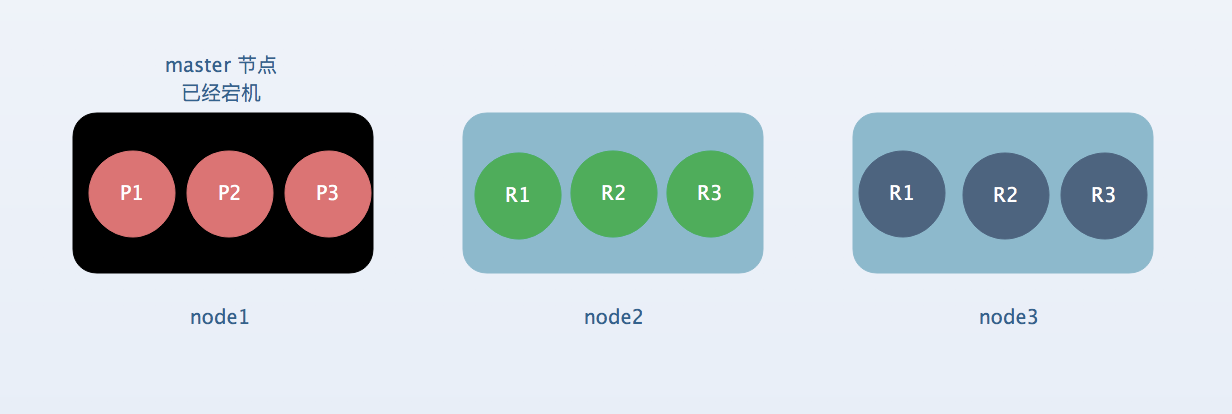
[1] : 容错第一步:master 选举,当master宕机的时候它所在的节点上面所有的分片数据会丢失,只能通过其他的非master节点来获取数据,这个时候其他非master节点会选举出一个新的master节点来充当集群中新的master节点。
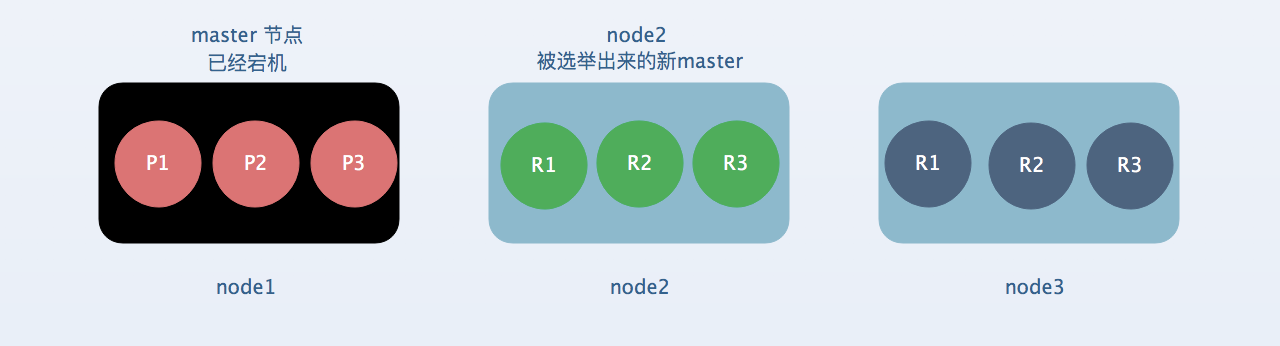 [2] : 容错第二步:,新的master会将丢失掉的master的其中一个replica shard提升为primary shard,此时cluster status会变成yellow,因为所有的primary shard 都变成active, 但是会缺少一个已经提升为primary shard的replica shard,所以不是所有的replica shard都是active。
[2] : 容错第二步:,新的master会将丢失掉的master的其中一个replica shard提升为primary shard,此时cluster status会变成yellow,因为所有的primary shard 都变成active, 但是会缺少一个已经提升为primary shard的replica shard,所以不是所有的replica shard都是active。
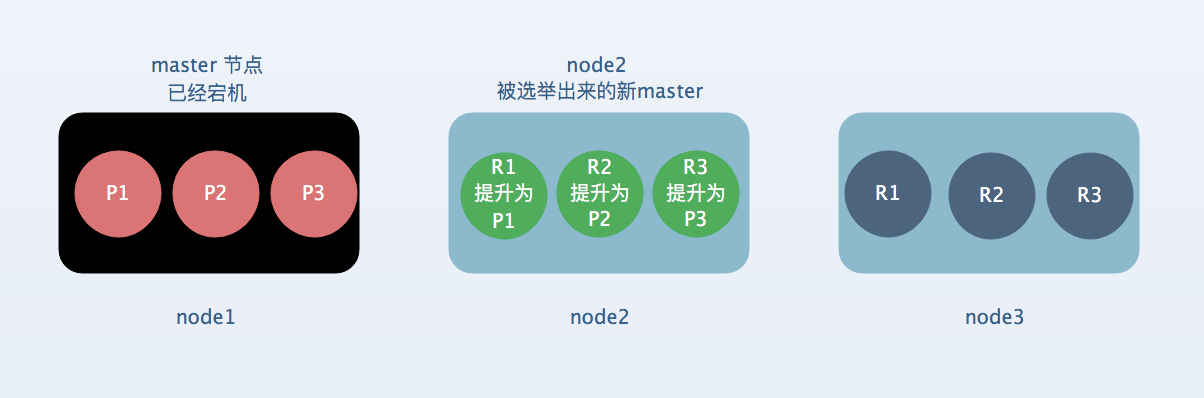
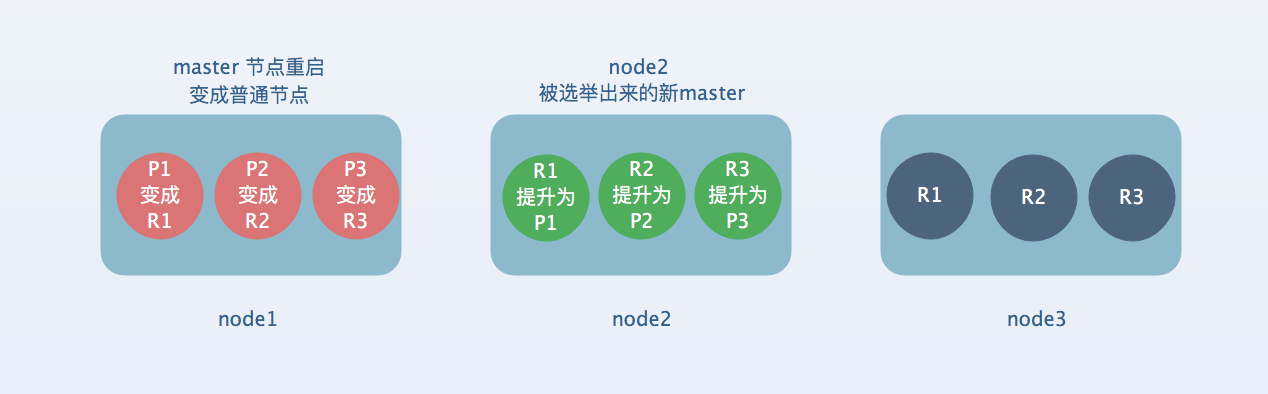
[3] : 容错第三步:重启故障的node,会将丢失的副本都copy到这个新的节点上面来,而且该node会使用之前已有的数据,只是同步了宕机过后发生的修改。cluster status 变成green,因为所有的primary shard和replica shard都齐全了。