






介绍
在我们使用mysql和elasticsearch结合使用的时候,可能会有一些同步的需求,想要数据库和elasticsearch同步的方式其实有很多。
可以使用canal,它主要是监听mysql的binlog 日志,可以监听数据的一些变化,如果数据发生了变化我们需要做什么逻辑,这些都是可以人为实现的,它是将自己模拟成一个slave节点,当master节点的数据发生变化是,它能够看到数据的变化。但是缺点也很明显,由于是java实现的,所以比较重,还需要使用zookeeper等集群管理工具来管理canal节点,所以本文暂时不介绍这种方式。
本文主要介绍使用Logstash JDBC的方式来实现同步,这个方式同步比较简单。当然它有一些缺点,就是有点耗内存(内存大就当我没说😂)。
最终效果展示
- 先看下ElasticSearch的数据, 这要好分辨效果,从响应结果可以看到现在有id为1,2,3的三条数据。 执行查询语句
GET /myapp/_search
{
"_source": "id"
}
响应结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "myapp",
"_type": "doc",
"_id": "2",
"_score": 1,
"_source": {
"id": 2
}
},
{
"_index": "myapp",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"id": 1
}
},
{
"_index": "myapp",
"_type": "doc",
"_id": "3",
"_score": 1,
"_source": {
"id": 3
}
}
]
}
}
- 现在我们来修改增加一条数据,看看es数据的变化 这里是数据库现在的数据, 可以看到里面有3条记录。
mysql> select * from user;
+------+----------+-------------+------------+-------+------------+---------+
| id | name | phone | password | title | content | article |
+------+----------+-------------+------------+-------+------------+---------+
| 1 | zhnagsan | 181222 | 123123 | ??? | ?????? | ???IE |
| 2 | lishi | 181222113 | 232123123 | 23??? | 234?????? | 4???IE |
| 3 | wangwu | 18111214204 | 1337547531 | ????? | lc content | Java |
+------+----------+-------------+------------+-------+------------+---------+
3 rows in set (0.00 sec)
mysql>
现在我们执行一个sql向里面添加一条数据
mysql> insert into user (id, name, phone, password, title, content, article) values (4, "lc", "123456789", "123456789", "测试", "测试内容", "Java")
Query OK, 1 row affected (0.00 sec)
mysql>
- 在次执行查询语句,看看es的数据变化,可以看到已经多了一条id为4的数据了,中间这个同步默认会有1分钟的延迟。 执行搜索
GET /myapp/_search
{
"_source": "id"
}
响应结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "myapp",
"_type": "doc",
"_id": "2",
"_score": 1,
"_source": {
"id": 2
}
},
{
"_index": "myapp",
"_type": "doc",
"_id": "4",
"_score": 1,
"_source": {
"id": 4
}
},
{
"_index": "myapp",
"_type": "doc",
"_id": "1",
"_score": 1,
"_source": {
"id": 1
}
},
{
"_index": "myapp",
"_type": "doc",
"_id": "3",
"_score": 1,
"_source": {
"id": 3
}
}
]
}
}
环境
Virtual machine:VMware 11.0.2 Operator System:CentOS release 6.9 (Final) ElasticSearch:6.4.0 Kibana版本:6.4.0 LogStash版本:6.6.1 JDK版本:1.8.0_181 MySQL版本: 5.1.73(这个版本是用yum直接安装的,其实这个教程和mysql版本没有多大关系,因为到时候是使用jdbc的驱动包来连接数据库的) logstash jdbc驱动包版本 5.1.46
获取需要的环境
本文暂时只提供下载地址(暂时偷个大懒 😄,安装顺序是按照链接排列顺序),logstash会给予详细使用说明,它是不需要安装的是需要解压就行了。 Virtual machine:VMware 11.0.2 Operator System:CentOS release 6.9 (Final) JDK版本:1.8.0_181 ElasticSearch:6.4.0 Kibana版本:6.4.0 Logstash版本:6.6.1 logStash驱动包
使用logstash
如果环境都安装好了可以看下面的了,没安装好也可以看😁
logstash 介绍
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
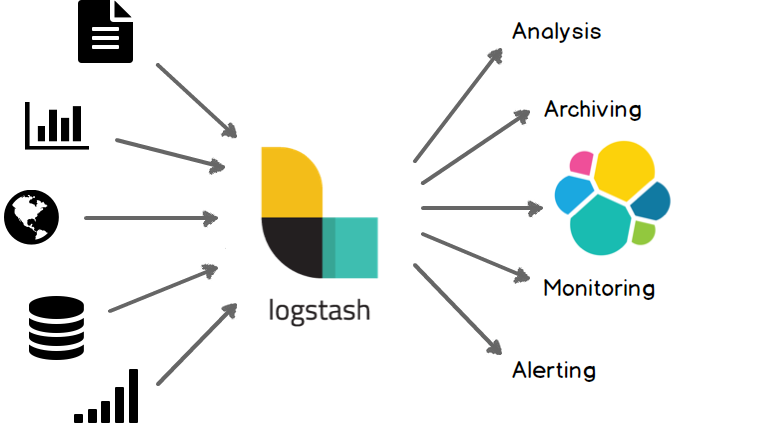
集中、转换和存储你的数据
Logstash是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储”。(当然,我们最喜欢的是Elasticsearch)
输入:采集各种样式、大小和来源的数据
数据往往以各种各样的形式,或分散或集中地存在于很多系统中。Logstash 支持各种输入选择 ,可以在同一时间从众多常用来源捕捉事件。能够以连续的流式传输方式,轻松地从您的日志、指标、Web 应用、数据存储以及各种 AWS 服务采集数据。
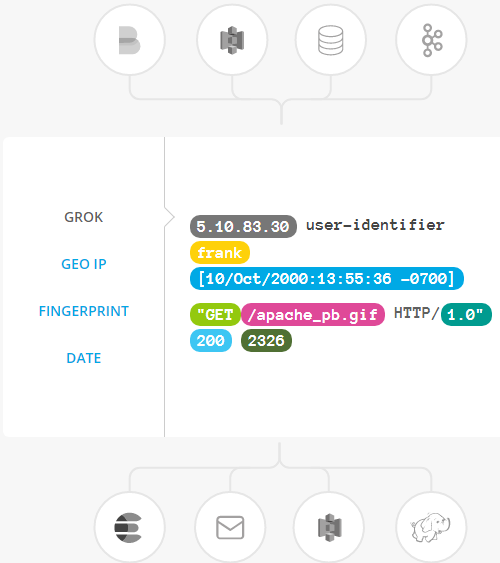
过滤器:实时解析和转换数据
数据从源传输到存储库的过程中,Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便更轻松、更快速地分析和实现商业价值。 Logstash 能够动态地转换和解析数据,不受格式或复杂度的影响:
- 利用 Grok 从非结构化数据中派生出结构
- 从 IP 地址破译出地理坐标
- 将 PII 数据匿名化,完全排除敏感字段
- 整体处理不受数据源、格式或架构的影响
输出:选择你的存储,导出你的数据
尽管 Elasticsearch 是我们的首选输出方向,能够为我们的搜索和分析带来无限可能,但它并非唯一选择。Logstash 提供众多输出选择,您可以将数据发送到您要指定的地方,并且能够灵活地解锁众多下游用例。
安装logstash
 首先,让我们通过最基本的Logstash管道来测试一下刚才安装的Logstash
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。
首先,让我们通过最基本的Logstash管道来测试一下刚才安装的Logstash
Logstash管道有两个必需的元素,输入和输出,以及一个可选元素过滤器。输入插件从数据源那里消费数据,过滤器插件根据你的期望修改数据,输出插件将数据写入目的地。
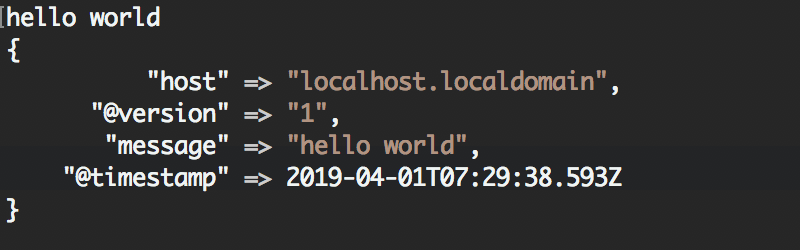
接下来,从命令行输入如下命令
bin/logstash -e 'input { stdin {} } output { stdout {} }'
选项 -e 的意思是允许你从命令行指定配置
当启动完成时,会等待你的输入,你可以输入hello world试试,它会给你一下信息的回馈。
使用logstash进行Mysql和ElasticSearch的同步
准备JDBC驱动包
-
首先,将我们刚才给予的下载链接里面的jdbc驱动包放到logstash目录里面来
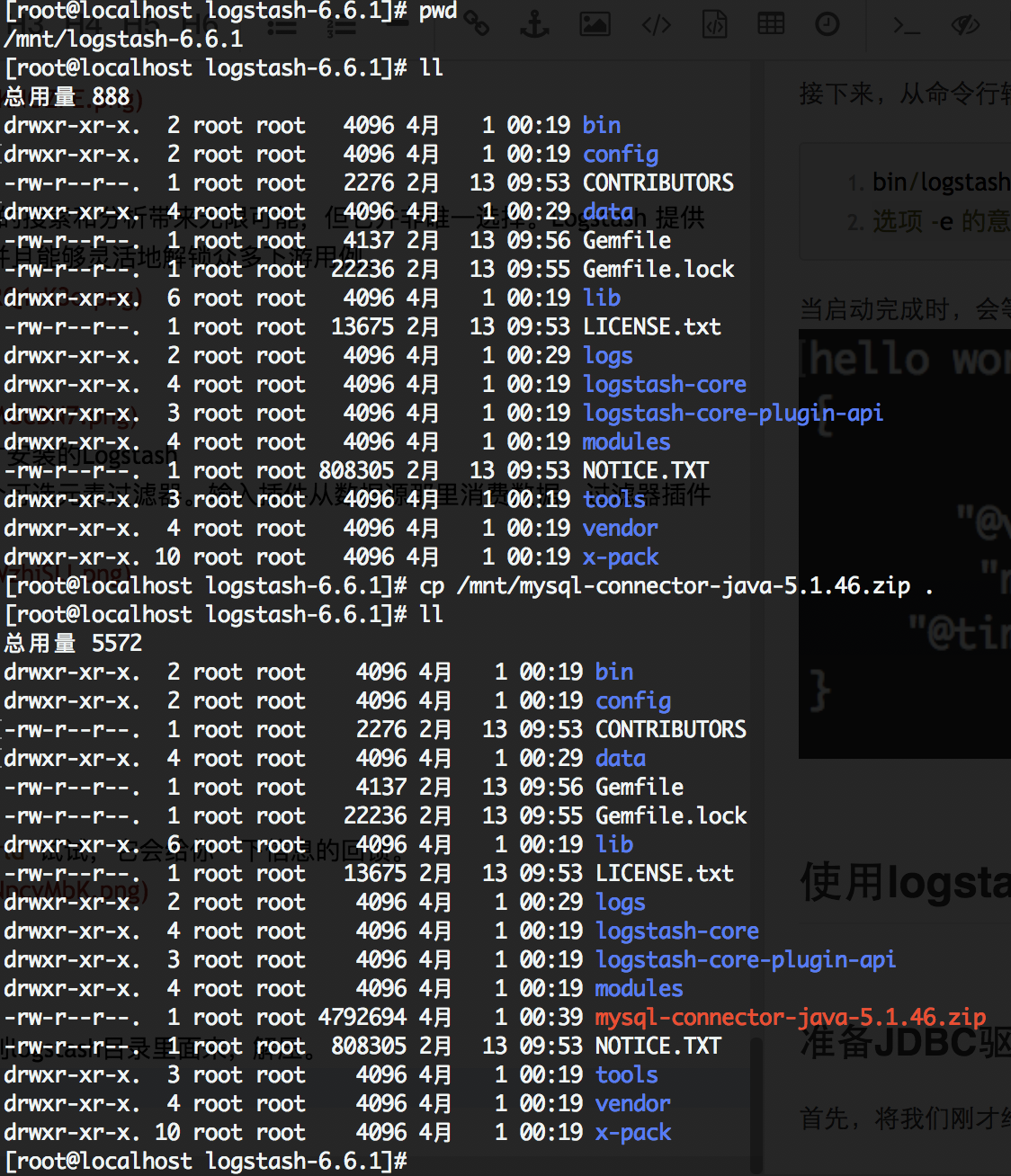
-
解压这个文件
[root@localhost logstash-6.6.1]# unzip mysql-connector-java-5.1.46.zip
生成mysqlsyn.conf文件
- 进入config目录,创建文件mysqlsyn.conf

- 使用vim编辑器打开这个文件,并向里面添加以下内容,并且保存退出。
input {
jdbc {
# jdbc驱动包位置
jdbc_driver_library => "/mnt/logstash-6.6.1/mysql-connector-java-5.1.46/mysql-connector-java-5.1.46-bin.jar"
# 要使用的驱动包类,有过java开发经验的应该很熟悉这个了,不同的数据库调用的类不一样。
jdbc_driver_class => "com.mysql.jdbc.Driver"
# myqsl数据库的连接信息
jdbc_connection_string => "jdbc:mysql://0.0.0.0:3306/myapp"
# mysql用户
jdbc_user => "root"
# mysql密码
jdbc_password => "root"
# 定时任务, 多久执行一次查询, 默认一分钟,如果想要没有延迟,可以使用 schedule => "* * * * * *"
schedule => "* * * * *"
# 你要执行的语句
statement => "select * from user"
}
}
output {
# 将数据输出到ElasticSearch中
elasticsearch {
# es ip加端口
hosts => ["0.0.0.0:9200"]
# es文档索引
index => "myusreinfo"
# es文档数据的id,%{id}代表的是用数据库里面记录的id作为文档的id
document_id => "%{id}"
}
}
启动logstash进行同步
上面我们已经生成了这个mysqlsyn.conf这个文件,接下来我们就使用logstash来进行数据同步吧,同步之前先看下我们的数据库的user表的数据。
-
查看mysql数据, 能够看到我们还是只有刚开始的4条数据
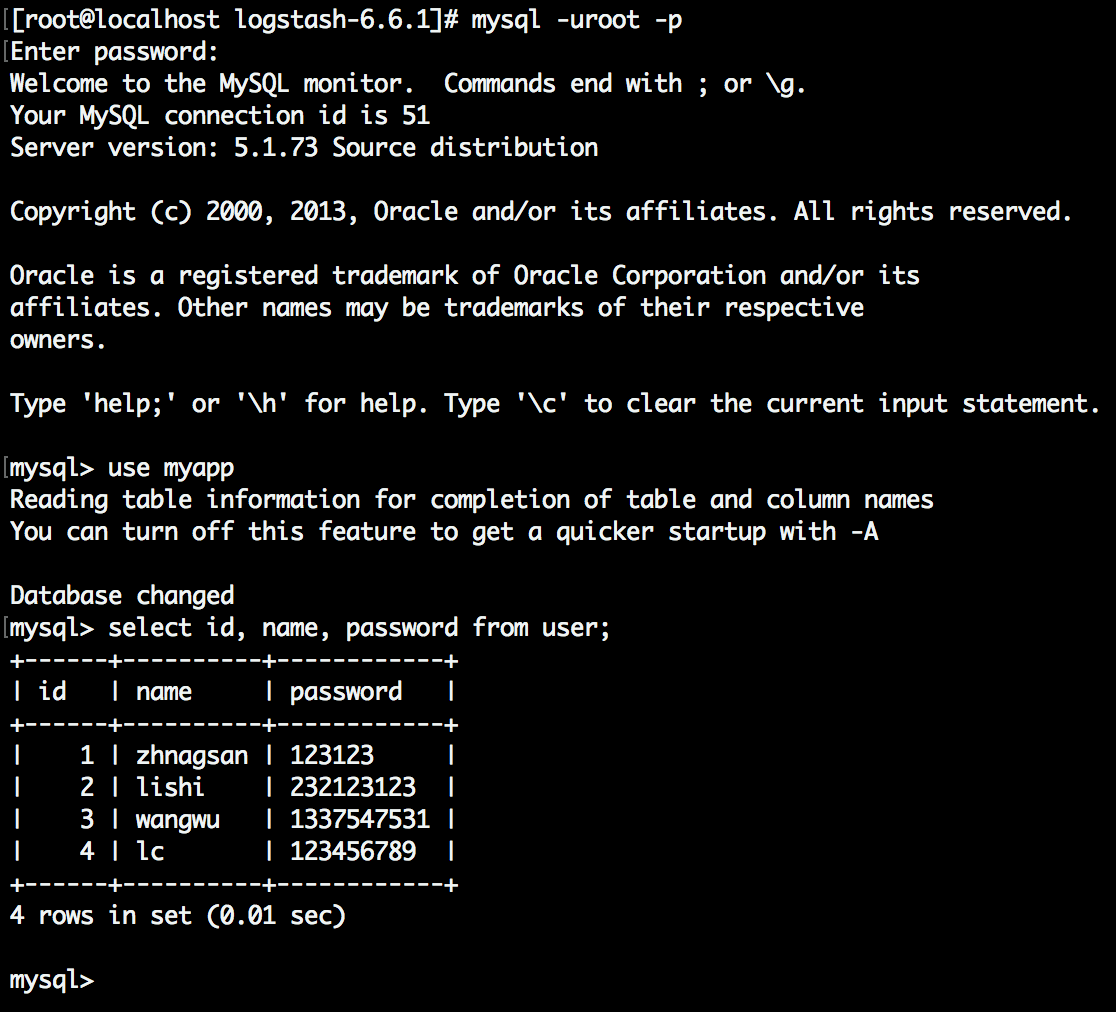
-
检查ElasticSearch是否有
myusreinfo这个索引,可以从图中看到我们只有myapp这个索引。
-
带上配置文件启动logstash
[root@localhost logstash-6.6.1]# ./bin/logstash -f config/mysqlsyn.conf
-f 指定配置文件启动
启动成功,并且已经在同步数据了,这个同步默认是每分钟执行一次,可以看到5分钟执行了5次
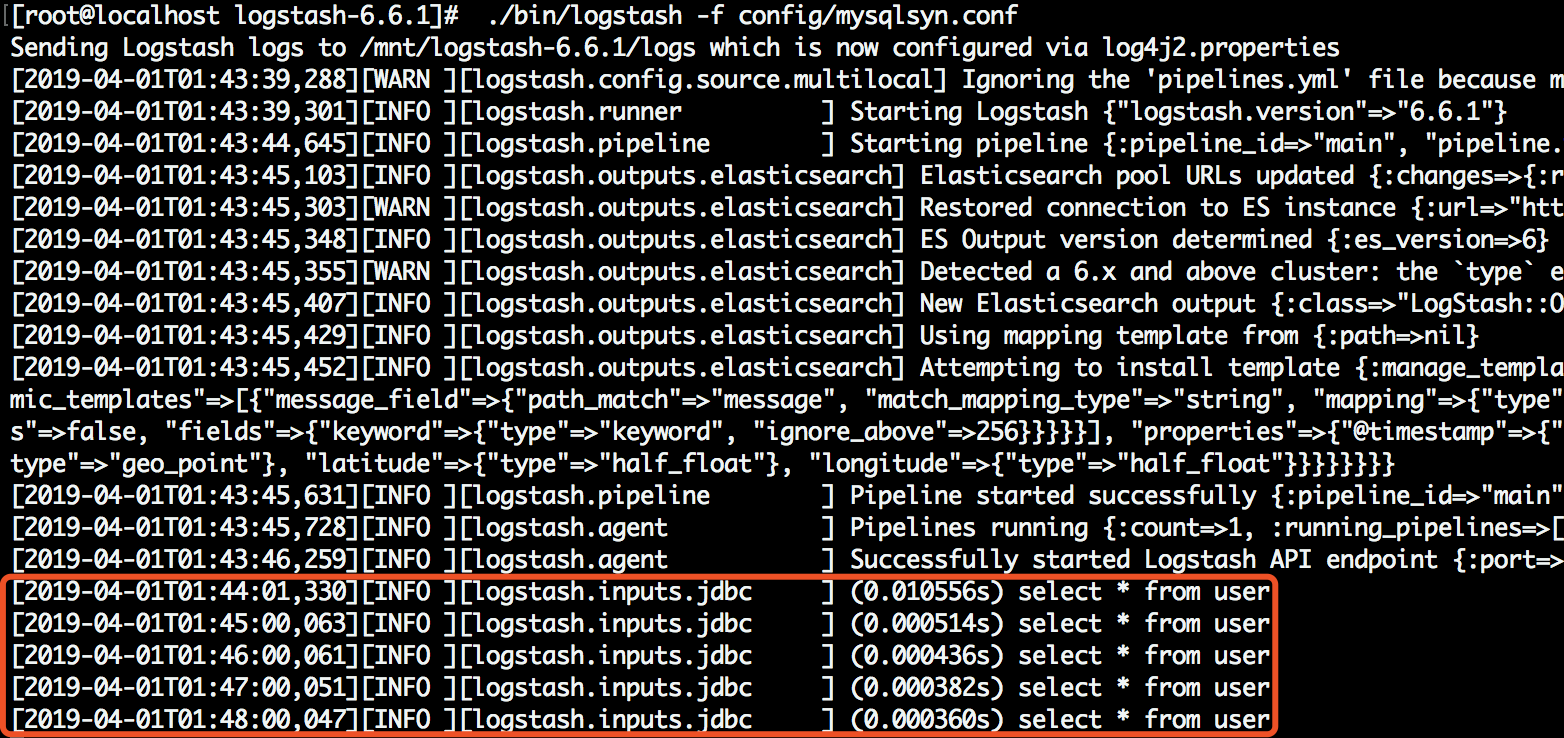
检查同步效果
-
上面已经启动了同步,现在我们去看看ElasticSearch里面的是否有数据,从图中可以看到myusrinfo已经同步到es里面了,并且可以看到
docs.count的数量就是我们刚才数据库里面数据的数量。
-
我们像数据库里面增加一条数据,然后看下ElasticSearch的数据是否会改变
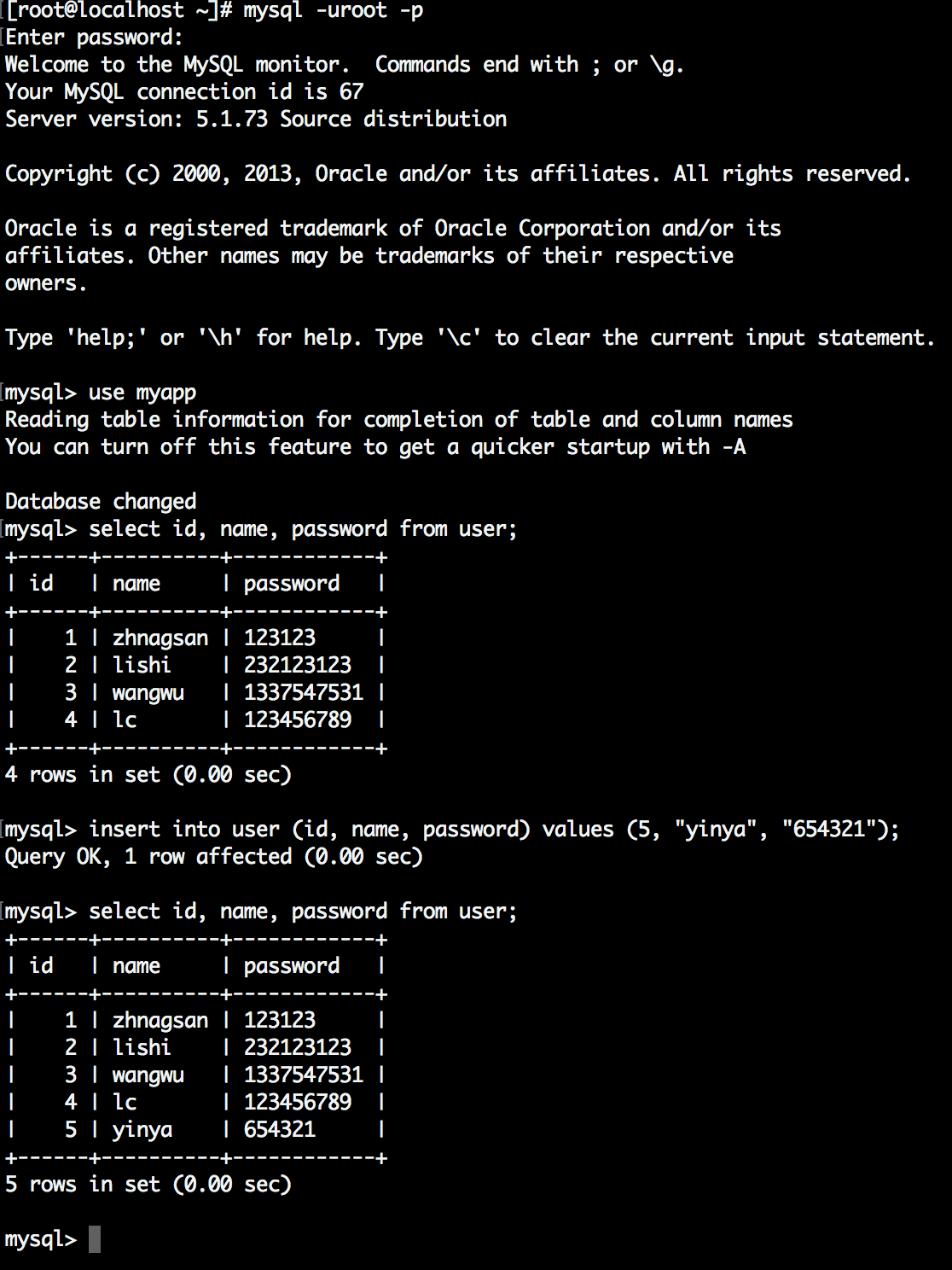
-
查看ElasticSearch里面是否有刚才添加的数据, 从图中可以看到已经有5条数据了

-
先看ElasticSearch里面id为5的数据,可以看到name为
yinya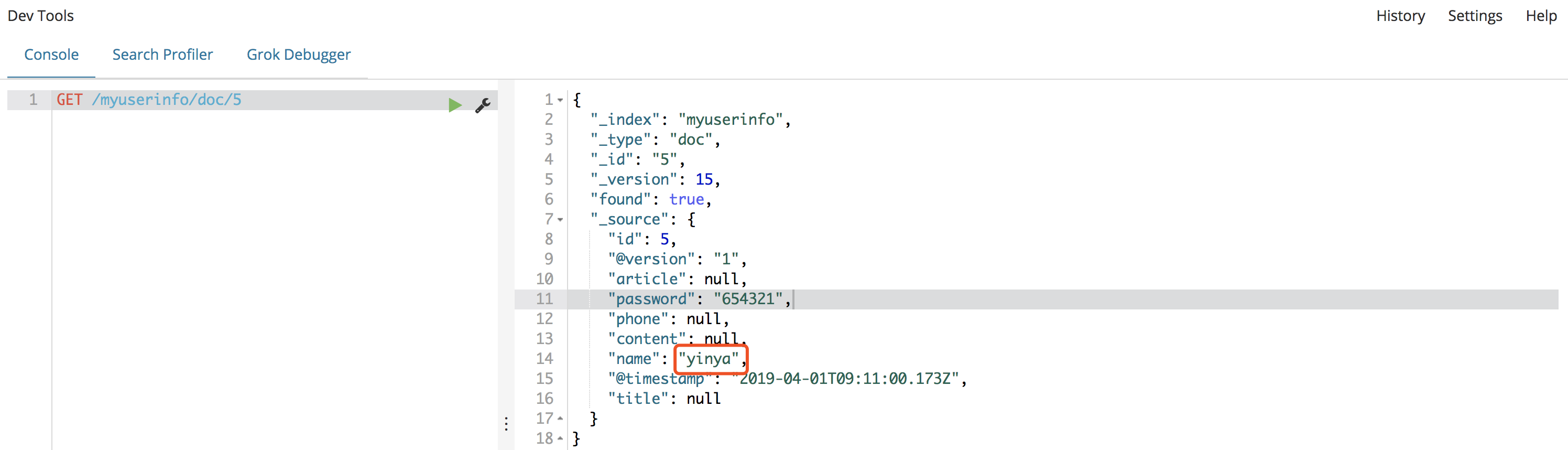
-
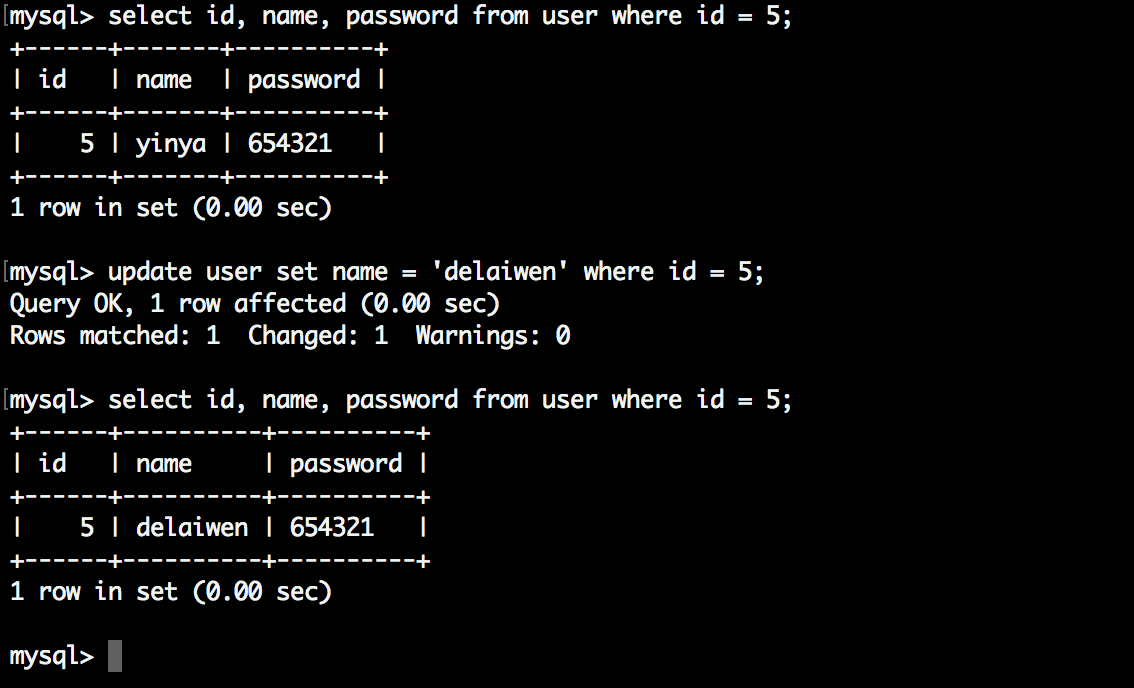
数据库修改一条id为5的数据,看看ElasticSearch的数据变化
-
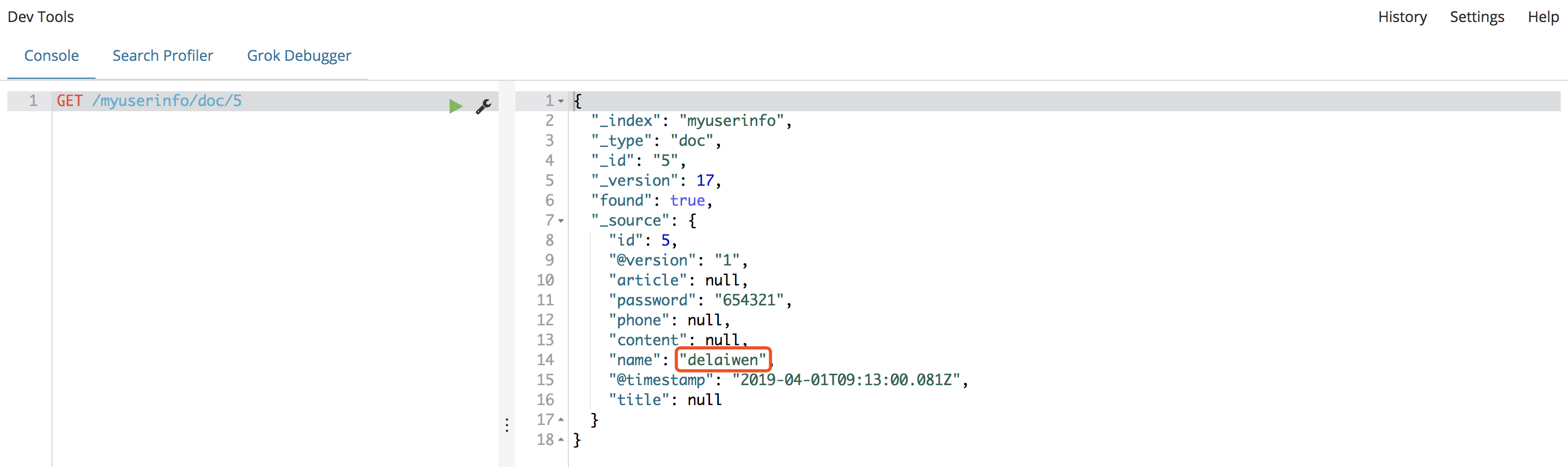
查看ElasticSearch里面数据是否已经更改,可以看到数据已经更改了
-
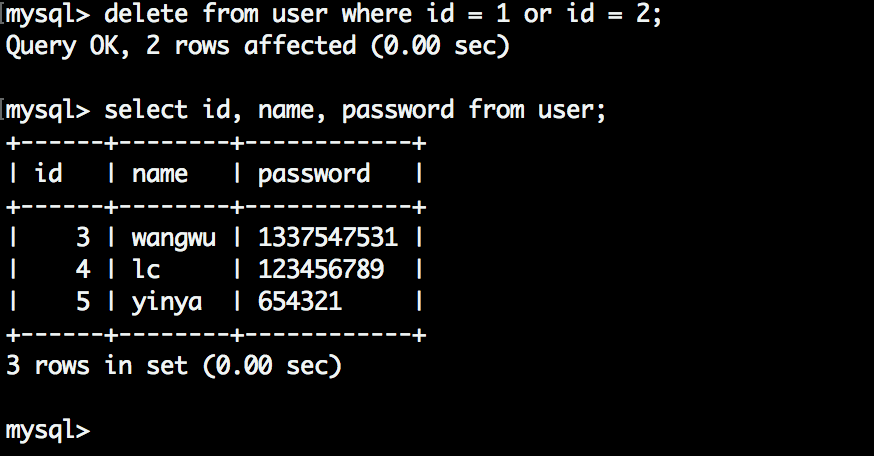
删除两条数据看看ElasticSearch数据的变化, 删除了id为1和2的两条数据
-
查看ElasticSearch里面数据是否已经更改, 然而数据并没有变

对delete操作的实时同步泼冷水
到目前为止,所有google,stackoverflow,elastic.co,github上面搜索的插件和实时同步的信息,告诉我们:目前同步delete还没有好的解决方案。 折中的解决方案如下: 方案探讨:https://discuss.elastic.co/t/delete-elasticsearch-document-with-logstash-jdbc-input/47490/9 http://stackoverflow.com/questions/34477095/elasticsearch-replication-of-other-system-data/34477639#34477639
-
方案一 在原有的mysql数据库表中,新增一个字段status, 默认值为ok,如果要删除数据,实则用update操作,status改为deleted, 这样,就能同步到es中。es中以status状态值区分该行数据是否存在。deleted代表已删除,ok代表正常。
-
方案二 使用go elasticsearch 插件实现同步。

