






介绍
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene(TM) 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,下面就介绍ElasticSearch为什么是分布式的,可扩展,高性能,高可用。
一,什么是搜索
在我们想知道一些信息时,就会使用一些搜索引擎来获取我们想要的数据,比如搜索我们喜欢的一款游戏,或者喜欢的一本书等等,这就是提到搜索的的第一印象,说直白点就是在任何场景下找寻你想要知道的信息,这就是搜索。
- 现在的搜索也称为垂直搜索 垂直搜索引针对某一个行业的专业搜索引擎,比如说电商网站,新闻网站,各种app内部等等,他们都是搜索引擎的细分和延伸,在抽取出需要的数据进行处理后再以某种形式返回给用户。
二,如果用数据库来做搜索会怎么样
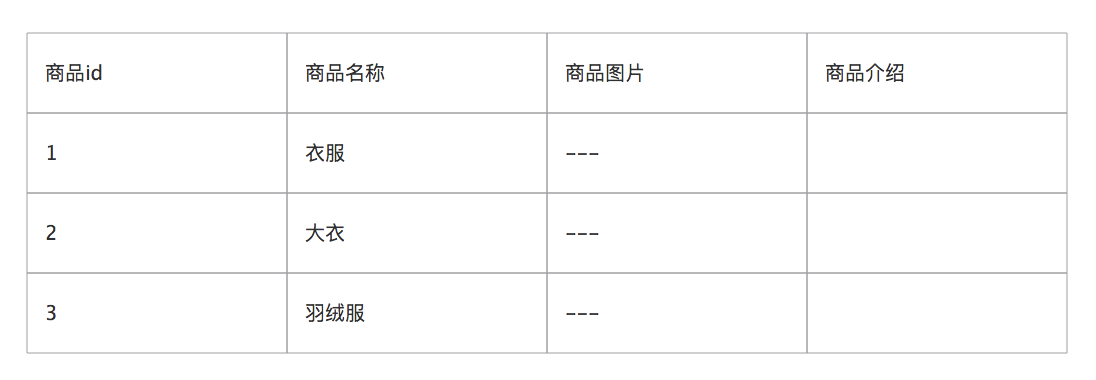
例如我们这里有一张商品表,现在我们要搜索"衣服"这个关键字,,执行了 select * from products where product_name like %衣服%,(假设这里没有其他任何提升效率的设置)来进行搜索,或者进行其他字段的匹配,可以分析一下这个方式的缺点。
弊端一,搜索过多无用字符
比如说,每条记录的指定字段的数据会很长,比如说**“商品介绍”**这个字段,可能会有几千或者几万个字符,那么搜索的时候就会去这些字符里面进行匹配是否包含要搜索的关键词。
弊端二,出现干扰字符可能导致搜索不准确
这种方式只能搜索到完全包含**“衣服”这个两个字符的记录,但是可能会有一些特殊的情况,某几条记录里面的“衣服”**关键词并不是连续的,可能衣服中间会插入某些字符,这个时候就搜索不出来这些记录了,但是这个商品又是我们希望搜索出来的,这个时候这种方式的弊端就十分明显了, 总的来说用数据库来实现搜索是不太靠谱的,性能会很差。
三,什么是全文检索
首先需要了解什么是倒排索引?我们这里先上一幅图,里面有4条记录。
 现在将这4条记录的内容进行拆分成一些词条,这个过程叫做分词
现在将这4条记录的内容进行拆分成一些词条,这个过程叫做分词
 现在我们得到了这4条记录拆分出来词语,然后将这写词语放到一个列表中,并记录他们的ID,这个分析出来的就是 倒排索引
现在我们得到了这4条记录拆分出来词语,然后将这写词语放到一个列表中,并记录他们的ID,这个分析出来的就是 倒排索引
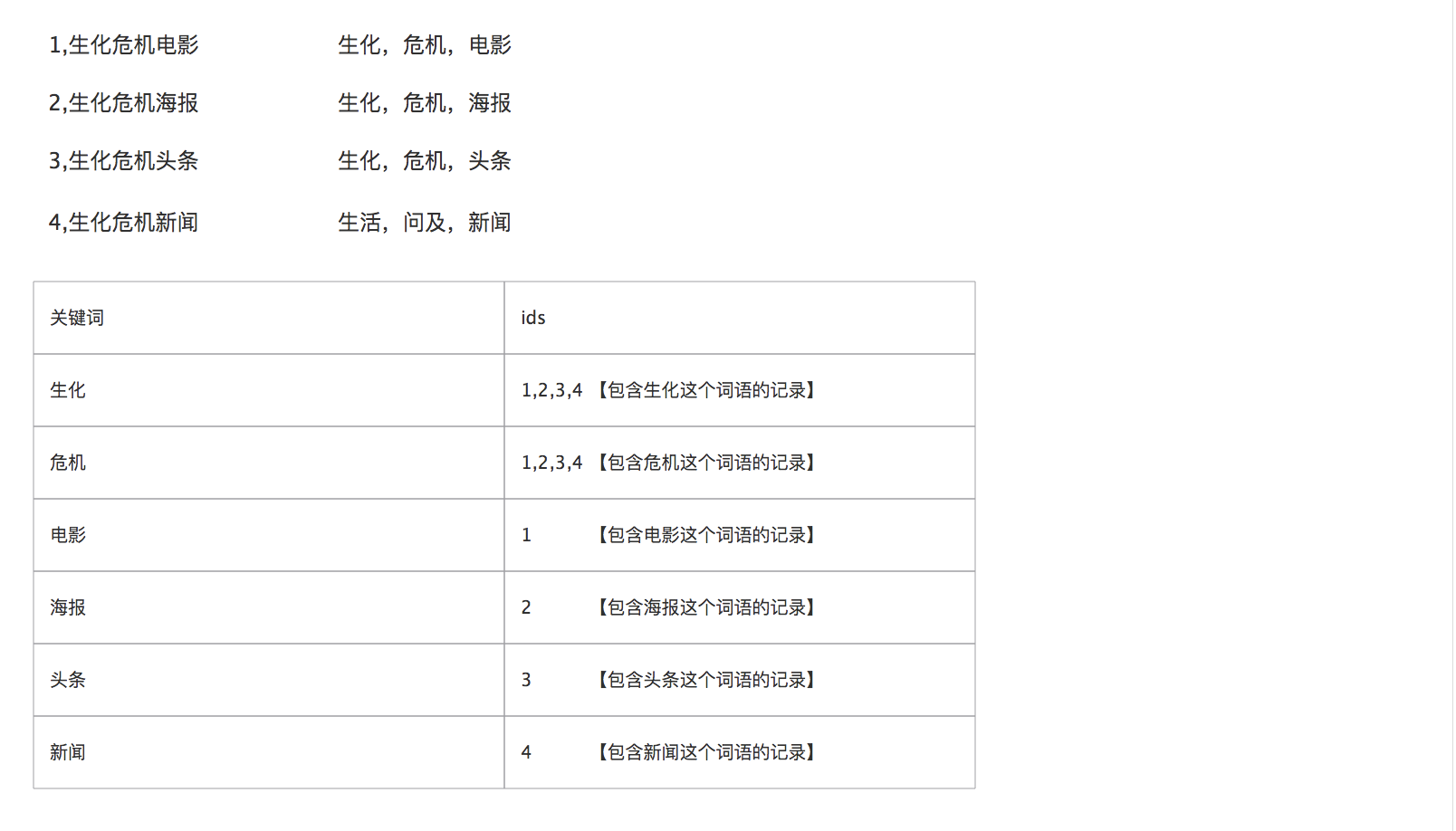 现在我们输入 生化电影 这个关键词,这个时候搜素引擎将我们输入的内容分词为 生化 和 电影 这两个关键词,然后使用这个两个关键词去倒排索引里面匹配,发现包含 生化 这个关键词的记录有ID为 1,2,3,4这四条记录,包含 电影 这个关键词的有ID为1这条记录,由于ID为1这条记录已经被录入了,所以就被排除在外了, 这时候我们就得到了想要ID为1234这4条记录,同理,如果我们只输入 电影 这个关键词,那么符合条件的只有ID为1这条记录了。
现在我们输入 生化电影 这个关键词,这个时候搜素引擎将我们输入的内容分词为 生化 和 电影 这两个关键词,然后使用这个两个关键词去倒排索引里面匹配,发现包含 生化 这个关键词的记录有ID为 1,2,3,4这四条记录,包含 电影 这个关键词的有ID为1这条记录,由于ID为1这条记录已经被录入了,所以就被排除在外了, 这时候我们就得到了想要ID为1234这4条记录,同理,如果我们只输入 电影 这个关键词,那么符合条件的只有ID为1这条记录了。
全文检索就是从拆分词语,存入倒排索引,然后分析用户输入的内容,在倒排索引里面进行匹配,这个过程就是全文检索。
四,什么是ElasticSearch
首先需要知道什么是Lucence,Lucence它就是一个Java的jar包,里面实现了倒排索引的算法和其他的全文检索相关的东西,ElasticSearch就是对Lunence进行了封装,为什么有Lucence了还要ElasticSeaearch来干什么呢?首先,当数据量很大的时候,比如有1PB的数据,这个时候数据放在同一台机器上基本就不行了,那么把数据分开来放在多台机器上呢?那就变成分布式了,这个时候数据前端获取数据的时候到底去那一台机器上面去获取数据呢?这个时候就很麻烦了,如果某一台机器宕机了,那么这个机器上的数据就获取不到了,这也就无法保证高可用性了,还有数据存储的时候怎么到底存入那台机器等等,这些都需要人为的处理和维护。这个时候ElasticSearch就应运而生了,它就将Lucence这些弊端给完全解决了。
ElasticSearch的优点
高性能,自动维护数据分布到多个节点进行索引的建立,还有搜索请求分布到多个节点的执行。
高可用,自动维护数据的冗余副本,保证说,一些机器宕机了,不会造成数据的丢失。
封装了更多的高级功能,以给我们提供更多的高级支持,让我们快速的开发应用,开发更加复杂的应用,复杂的搜索功能,聚合分析的功能,基于地理位置的搜索(比如周围一公里内有几家咖啡厅)等等。
动态扩容,当我们数据量急剧提升的时候,我们只需要增加机器就行了,比如两台机器存放1.2T数据,那么没台机器存放就是600G,但是如果600G对于服务器的压力太大了,这个时候就需要增加第三台机器,让他们每人负责400G的数据,这个过程不需要人为的去分配,只需要将汲取加入集群中就自动完成。
