






介绍
本文将介绍我是如何在python爬虫里面一步一步踩坑,然后慢慢走出来的,期间碰到的所有问题我都会详细说明,让大家以后碰到这些问题时能够快速确定问题的来源。
流程一览
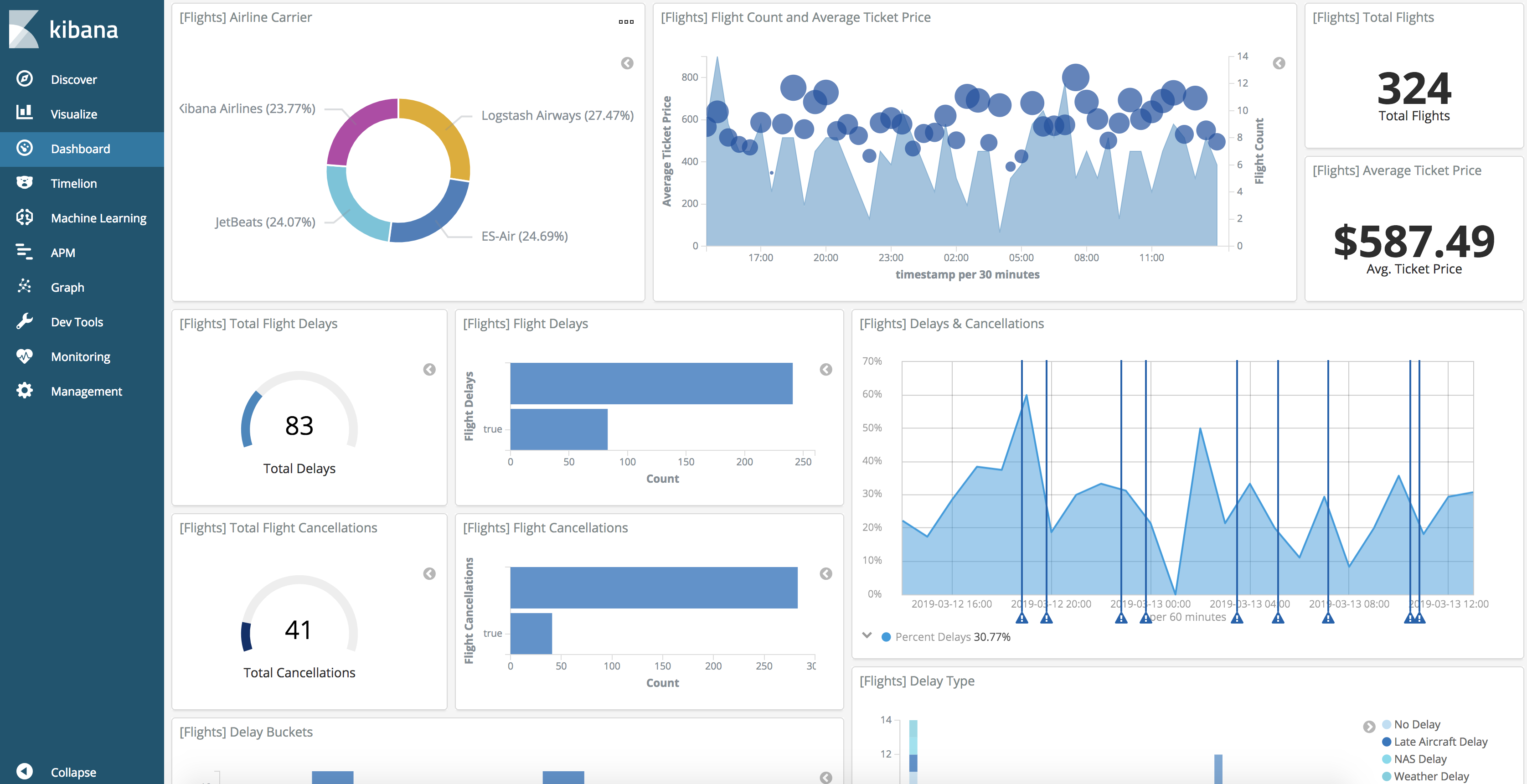
首先我是想爬某个网站上面的所有文章内容,但是由于之前没有做过爬虫(也不知道到底那个语言最方便),所以这里想到了是用python来做一个爬虫(毕竟人家的名字都带有爬虫的含义😄),我这边是打算先将所有从网站上爬下来的数据放到ElasticSearch里面, 选择ElasticSearch的原因是速度快,里面分词插件,倒排索引,需要数据的时候查询效率会非常好(毕竟爬的东西比较多😄),然后我会将所有的数据在ElasticSearch的老婆kibana里面将数据进行可视化出来,并且分析这些文章内容,可以先看一下预期可视化的效果(上图了),这个效果图是kibana6.4系统给予的帮助效果图(就是说你可以弄成这样,我也想弄成这样😁)。后面我会发一个dockerfile上来(现在还没弄😳)。
弄完这个爬虫会学到那些知识点
如果能按照我的入坑和出坑,你应该可以get到这些东西,而且还会灵活的使用它(因为你在开发的时候会一直使用它们去调试,所以你就用的6了)
- ElasticSearch 的安装及基本使用(Mapping的建立,数据的查找,以及索引的删除,和索引数据迁移)
- Kibana 的安装和使用(kibana的可视化界面应该配置那些东西,慢慢的一步一步达到开篇的那张图片的效果)
- python的scrapy库的使用以及注意事项
- redis的安装以及使用(这里面我用redis来去除重复链接,scrapy是自带去除重复链接的,但是如果使用自带的过滤属性就没法一直跑全网站的链接了)
环境需求
- Jdk (Elasticsearch需要)
- ElasticSearch (用来存储数据)
- Kinaba (用来操作ElasticSearch和数据可视化)
- Python (编写爬虫)
- Redis (数据排重)
这些东西可以去找相应的教程安装,我这里只有ElasticSearch的安装😢点我获取安装教程
第一步,使用python的pip来安装需要的插件(第一个坑在这儿)
- tomd:将html转换成markdown
pip3 install tomd
- redis:需要python的redis插件
pip3 install redis
- scrapy:框架安装(坑)
- 首先我是像上面一样执行了
pip3 install scrapy- 然后发现缺少
gcc组件error: command 'gcc' failed with exit status 1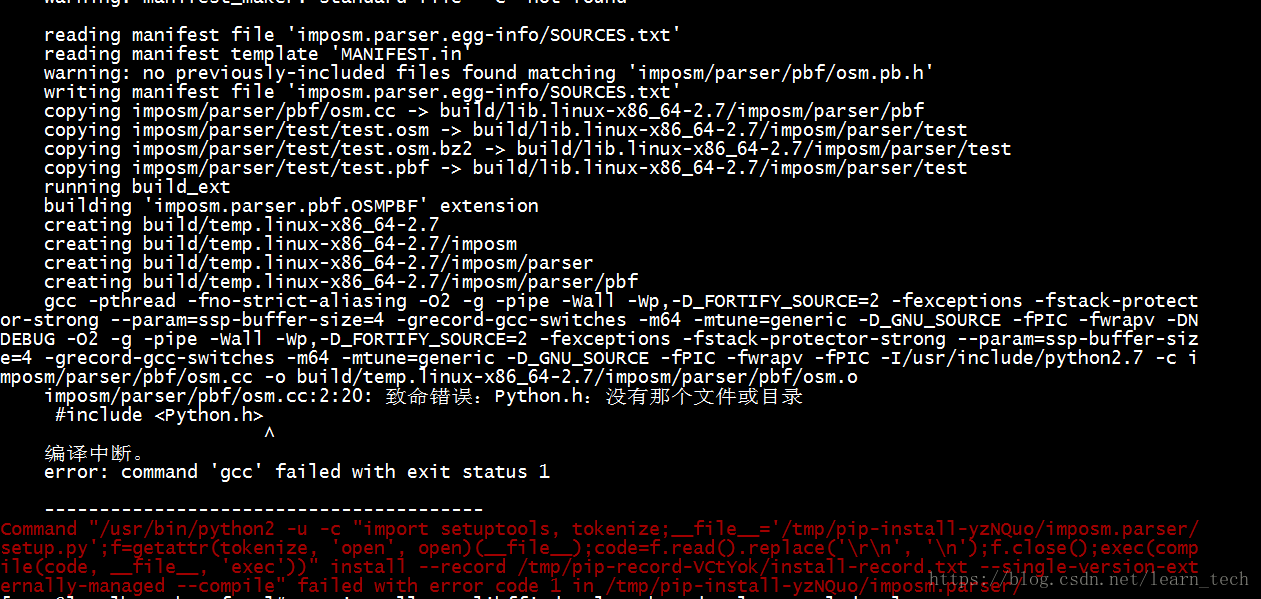
- 然后我就找啊找,找啊找,最后终于找到了正确的解决方法(期间试了很多错误答案😭)。最终的解决办法就是使用
yum来安装python34-devel, 这个python34-devel根据你自己的python版本来,可能是python-devel,是多少版本就将中间的34改成你的版本, 我的是3.4.6
yum install python34-devel- 安装完成过后使用命令 scrapy 来试试吧。
第二步,使用scrapy来创建你的项目
- 输入命令
scrapy startproject scrapyDemo, 来创建一个爬虫项目
liaochengdeMacBook-Pro:scrapy liaocheng$ scrapy startproject scrapyDemo
New Scrapy project 'scrapyDemo', using template directory '/usr/local/lib/python3.7/site-packages/scrapy/templates/project', created in:
/Users/liaocheng/script/scrapy/scrapyDemo
You can start your first spider with:
cd scrapyDemo
scrapy genspider example example.com
liaochengdeMacBook-Pro:scrapy liaocheng$
- 使用genspider来生成一个基础的spider,使用命令
scrapy genspider demo juejin.im, 后面这个网址是你要爬的网站,我们先爬自己家的😂
liaochengdeMacBook-Pro:scrapy liaocheng$ scrapy genspider demo juejin.im
Created spider 'demo' using template 'basic'
liaochengdeMacBook-Pro:scrapy liaocheng$
- 查看生成的目录结构
第三步,打开项目,开始编码
- 查看生成的的demo.py的内容
# -*- coding: utf-8 -*-
import scrapy
class DemoSpider(scrapy.Spider):
name = 'demo' ## 爬虫的名字
allowed_domains = ['juejin.im'] ## 需要过滤的域名,也就是只爬这个网址下面的内容
start_urls = ['http://juejin.im/'] ## 初始url链接
def parse(self, response): ## 如果新建的spider必须实现这个方法
pass

